Lukas Munzel Take-Home-Interview
Environment
Tasks feature requests or bug fixes for NetworkX, a python package for creating, manipulating and analyzing graphs with over 4k pull requests in total. Conveniently, it also has over 90% code coverage.
The environment is simply a docker image of the NetworkX package as of the last commit on August 31st, 2025. Naturally, different tasks are sandboxed in different containers, though they are all based on the same image
Tasks
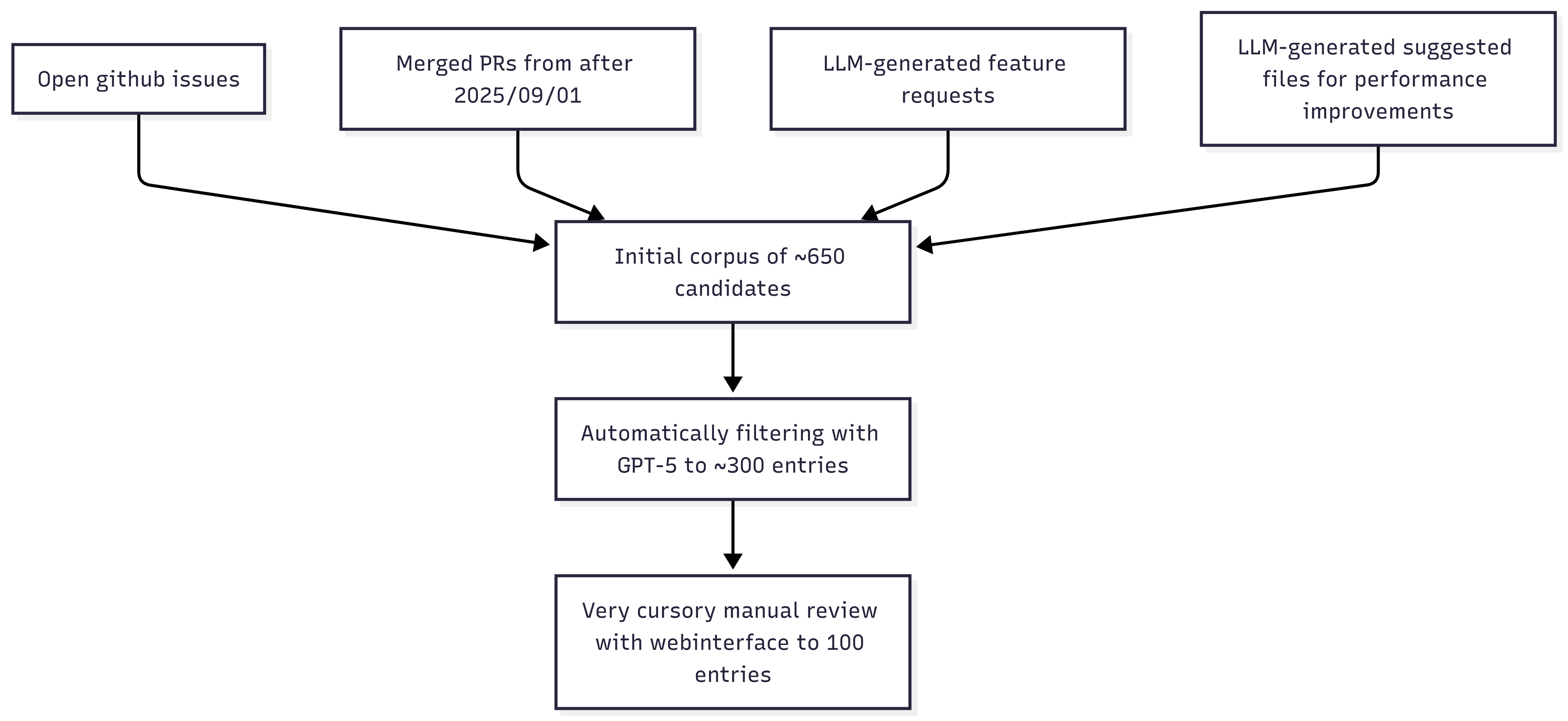
We then get task from the following four sources: 1) Open github issues on the repo 2) Merged pull requests starting from September 1st, 2025 (after all of OpenAI’s and Anthropic’s current model’s training cutoffs) 3) Claude code & codex being queried to suggest new features 4) Claude code & codex being queried to suggest methods/algorithms that could be sped up significantly
For both 1) and 2), we first automatically filter for self-contained and reasonably well-defined problems with GPT 5.2 thinking. For all tasks, we allow for very cursory manual filtering with an interface developed for that exact
C[Initial corpus of ~650 candidates]
MM[Merged PRs from after 2025/09/01] --> C
V[LLM-generated feature requests] --> C
L[LLM-generated suggested files for performance improvements] --> C
C --> O[Automatically filtering with GPT-5 to ~300 entries]
O --> B[Very cursory manual review with webinterface to 100 entries] ``` -->
Evaluation & Scoring
First, we check that none of the existing tests in the repo were modified (and reject the solution if they were). Then we call a claude code instance with 4.5 haiku to generate additional tests for the given problem & run those as well as all the existing tests.
For regular problems, we then just directly return a score of 1.0 if all tests are passed and 0.0 otherwise.
For performance benchmarking, we ask claude code to create a benchmark with a few reasonably big graphs. We then benchmark the CPU time required to get the speedup factors for each graph and compute their geometric mean \(m\).
If any output is incorrect, we return a score of \(0\). Otherwise, we return \(\tanh(\max(0,(\log_{10}(m)))\). Since the range on \(\tanh\) is \([0,1)\) on \([0, \infty)\), we get that this score is in \([0,1)\)
Results
When I started running tests on the more than just a few cases, I realized that it seems like the non-performance-benchmark tests basically always pass as long as the mini-swe-agent does not attempt to modify any existing test cases. I very quickly running out of time to debug this, and am therefore now just trying to report on the performance benchmark, which seems to be working:
Welp, runnning these even with 70 instances running in parallel is taking a while. Will upload results to online report when they come in:
Further work
Important caveat: the entire codebase is vibecoded with claude 4.5 opus - I read 20 - 30% of the codebase. I would hence want to properly read through all code before putting this into production. Also I would really like to have a nicer logging interface for both the actions of the mini-swe-agent as well as the evaluation by claude code - one could very well imagine also e.g. automatically generating summaries of the code sessions & evaluation, showing those, and sorting failure modes automatically.
I would strongly expect that some very low hanging fruits for improvements would thereby become obvious. Also I think the scores currently attained almost feel too good for tasks other than the performance benchmarking - we should thus either query for harder tasks or properly check whether the automatic evaluation pipeline might not have tend towards having false positives (!)
It also turns out that the 300s - 600s timeout we set quite often kills either our claude code instance or the benchmarking script. Note that we ask the claude code to create performance benchmarks that take at most 1 - 3 minutes to run, but then occasionally crossing the five minute mark is to be expected.
One very obvious improvement would be to have claude code write the tests & benchmarking code only once and have this is a part of the environment.
Scaling
We can immediately scale the automatically generated feature requests & suggested algorithms/files for performance improvement.
Another obvious dimension would be to scale our approach across different repos. One would naturally ideally like to avoid any manual effort here in any aspect other than perhaps selecting which repos to include. Hence I think one would want to find good prompts for getting good automatic filters & perhaps even train models to suggest interesting new modifications to the codebase
Remarks
Open issues were surprisingly bad training data - quite a few come from users who do not put adequate care into phrasing their question. Very often, an open issue also revolves around how to design the api in a more user-friendly way - a task for which does is not readily verifiable